
I am a fifth-year Ph.D. candidate in Artificial Intelligence at Seoul National University, where I am part of SNU Computer Vision Lab under the supervision of Prof. Kyoung Mu Lee (Editor in Chief of TPAMI). I received B.S. in Statistical Modeling Data Science at The Pennsylvania State University.
Previously, I was also part of SONY and KAIST as a visiting researcher.
My main research agenda is 3D Virtual Human for Extended Reality (XR), Robotics, Interactive Entertainment, and Autonomous Driving.
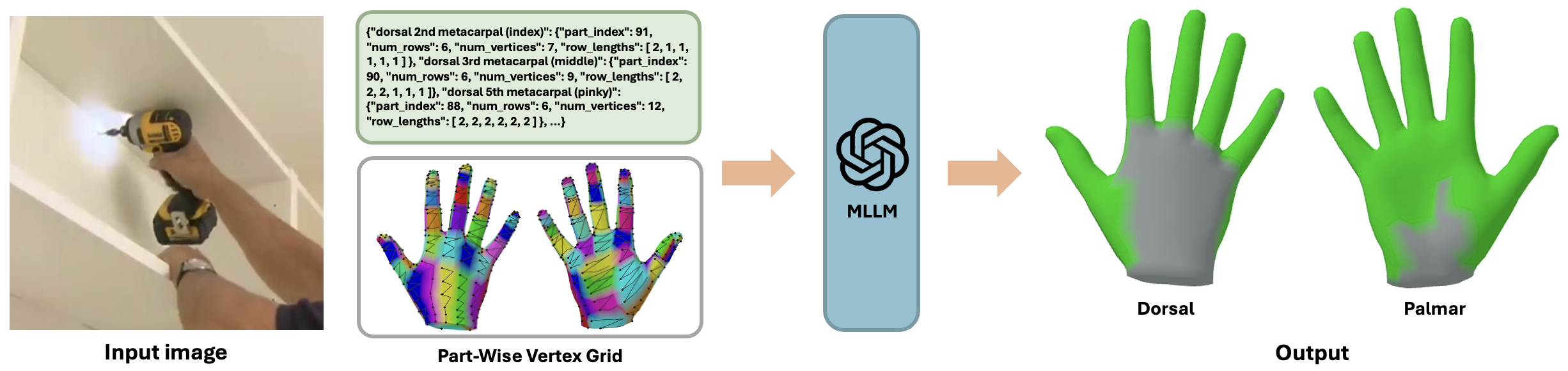 Training-Free Dense Hand Contact Estimation with Multi-Modal Large Language Models
Training-Free Dense Hand Contact Estimation with Multi-Modal Large Language Models
Daniel Sungho Jung, Kyoung Mu Lee
arXiv, 2026
project page /
paper /
arxiv /
code
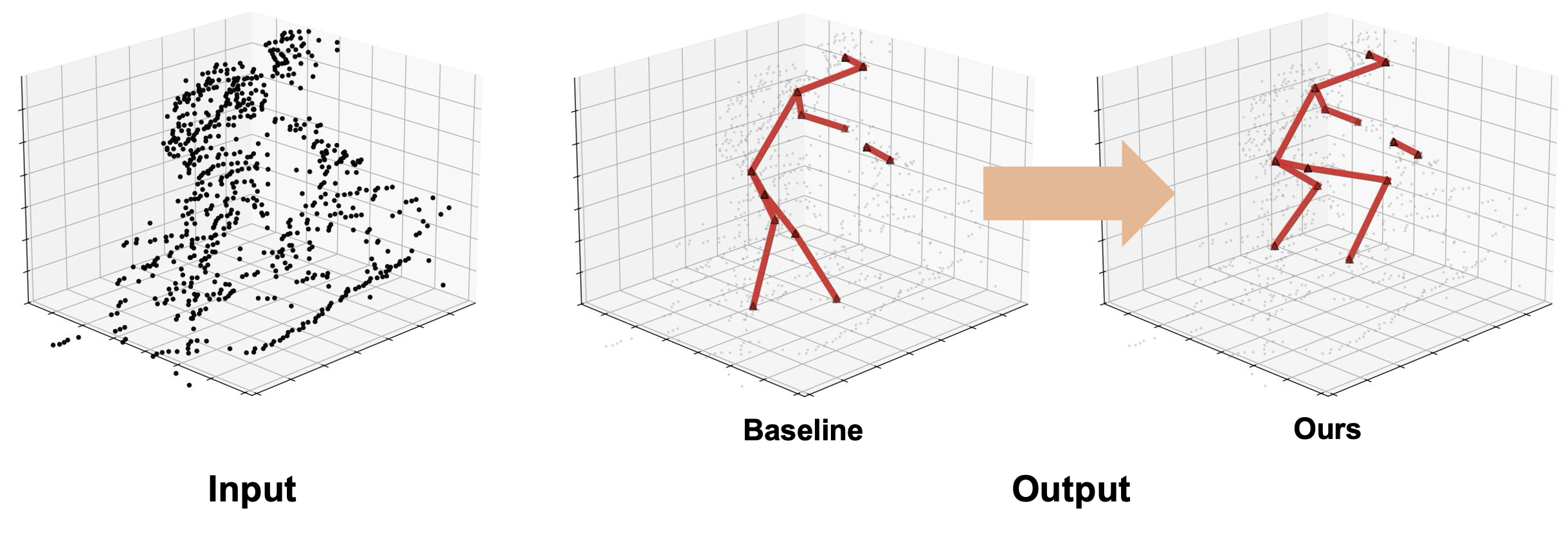 Learning Human-Object Interaction for 3D Human Pose Estimation from LiDAR Point Clouds
Learning Human-Object Interaction for 3D Human Pose Estimation from LiDAR Point Clouds
Daniel Sungho Jung, Dohee Cho, Kyoung Mu Lee
arXiv, 2026
project page /
paper /
arxiv
 PrintAnything: Learning Geometric Plan Map for 3D Printing G-code Generation from Unoriented Point Clouds
PrintAnything: Learning Geometric Plan Map for 3D Printing G-code Generation from Unoriented Point Clouds
Sangmin Hong, Daniel Sungho Jung, Heewon Kim, Kyoung Mu Lee
European Conference on Computer Vision (ECCV), 2026
 TeHOR: Text-Guided 3D Human and Object Reconstruction with Textures
TeHOR: Text-Guided 3D Human and Object Reconstruction with Textures
Hyeongjin Nam, Daniel Sungho Jung, Kyoung Mu Lee
Conference on Computer Vision and Pattern Recognition (CVPR), 2026
project page /
paper /
arxiv /
code /
Highlight
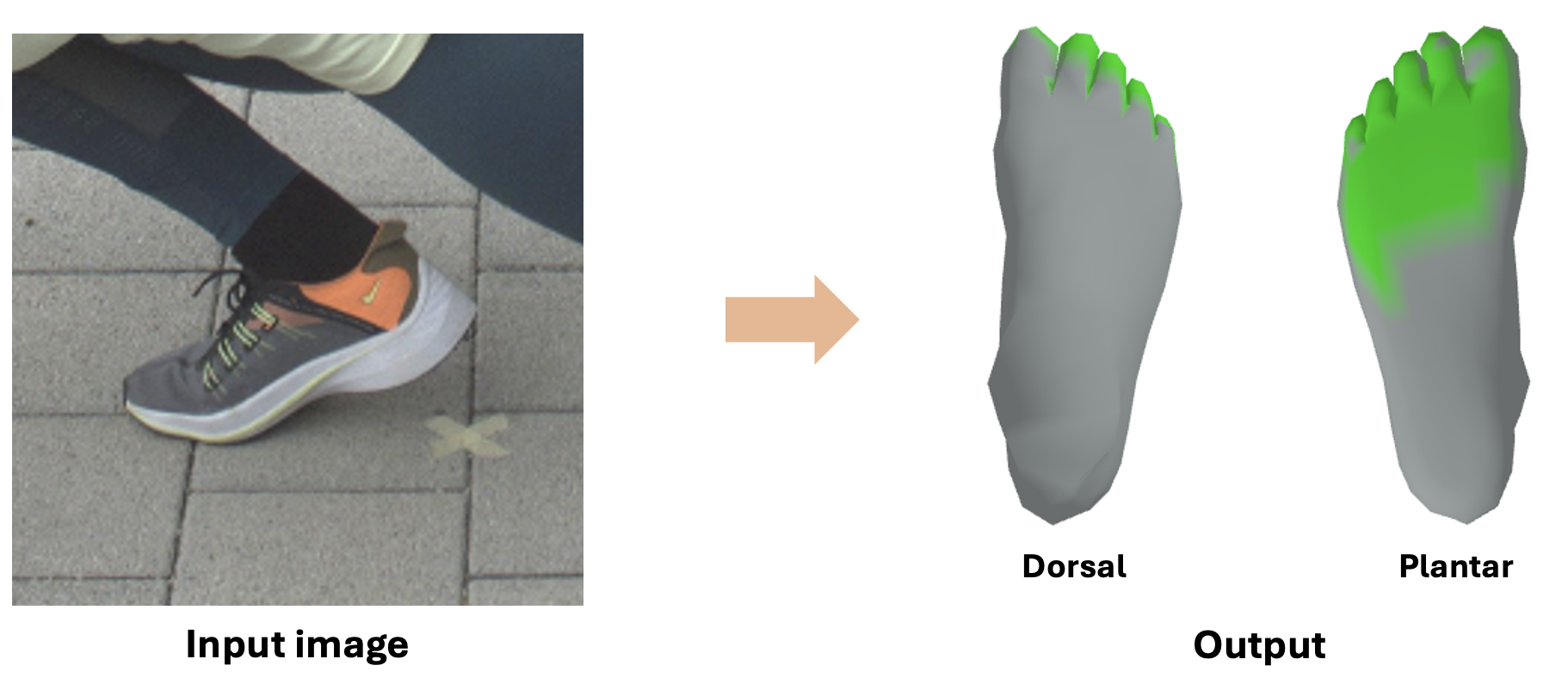 Shoe Style-Invariant and Ground-Aware Learning for Dense Foot Contact Estimation
Shoe Style-Invariant and Ground-Aware Learning for Dense Foot Contact Estimation
Daniel Sungho Jung, Kyoung Mu Lee
Conference on Computer Vision and Pattern Recognition (CVPR), 2026
project page /
paper /
arxiv /
code
 Learning Dense Hand Contact Estimation from Imbalanced Data
Learning Dense Hand Contact Estimation from Imbalanced Data
Daniel Sungho Jung, Kyoung Mu Lee
Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
project page /
paper /
arxiv /
code /
demo
 SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
Jaerin Lee, Daniel Sungho Jung, Kanggeon Lee, Kyoung Mu Lee
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
project page /
paper /
arxiv /
code /
demo /
500+ GitHub Stars
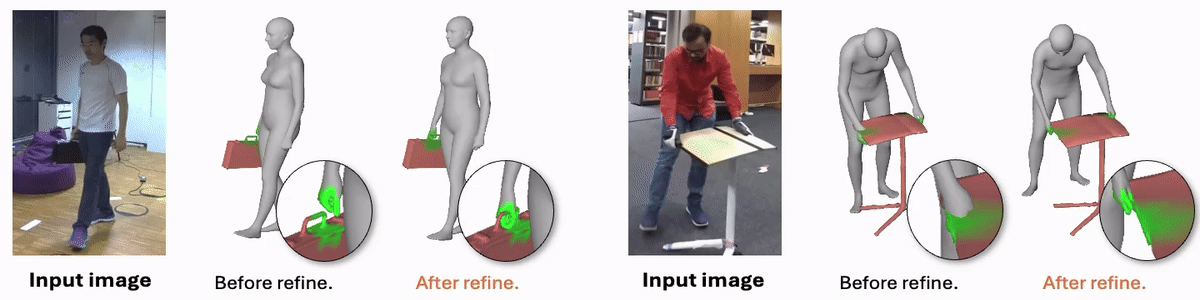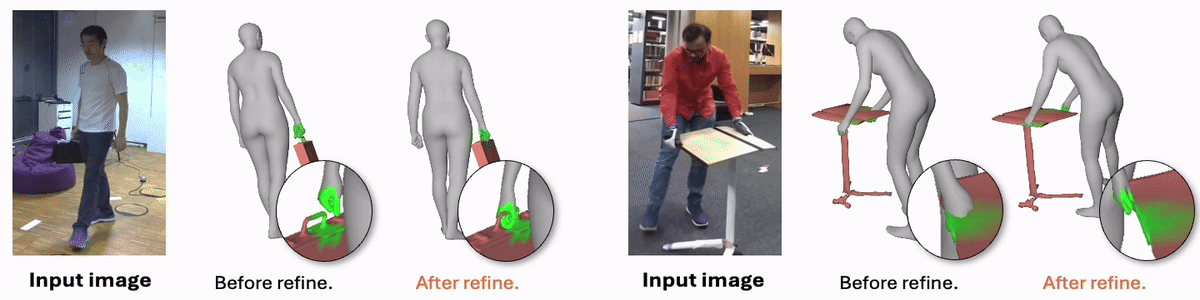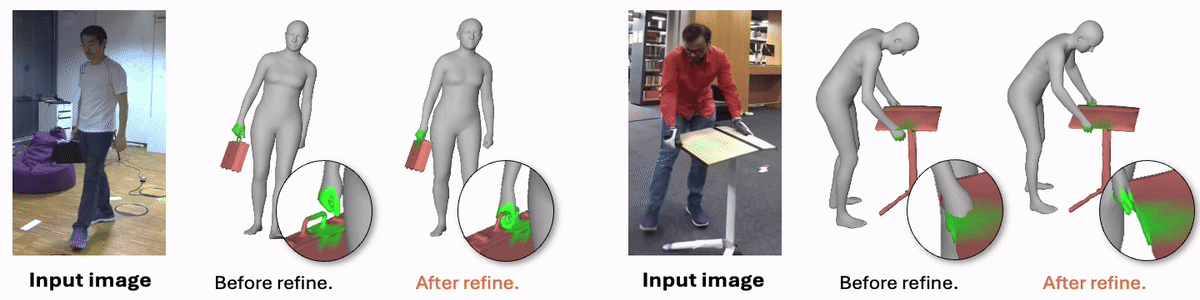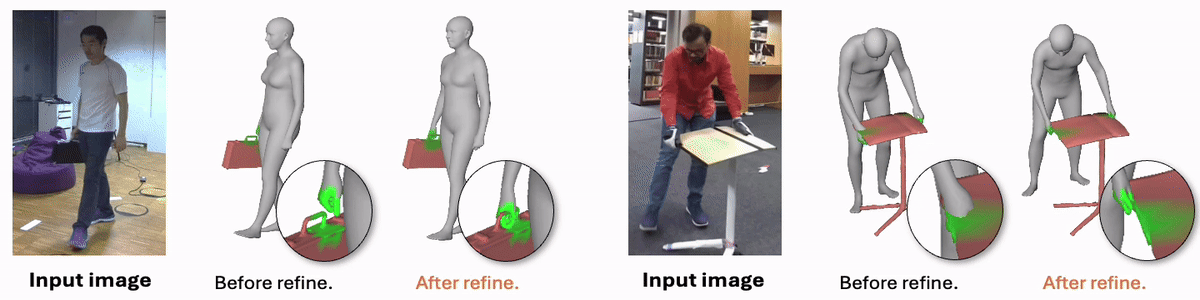 Joint Reconstruction of 3D Human and Object via Contact-Based Refinement Transformer
Joint Reconstruction of 3D Human and Object via Contact-Based Refinement Transformer
Hyeongjin Nam*, Daniel Sungho Jung*, Gyeongsik Moon, Kyoung Mu Lee (* equal contribution)
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
project page / paper / arxiv / code
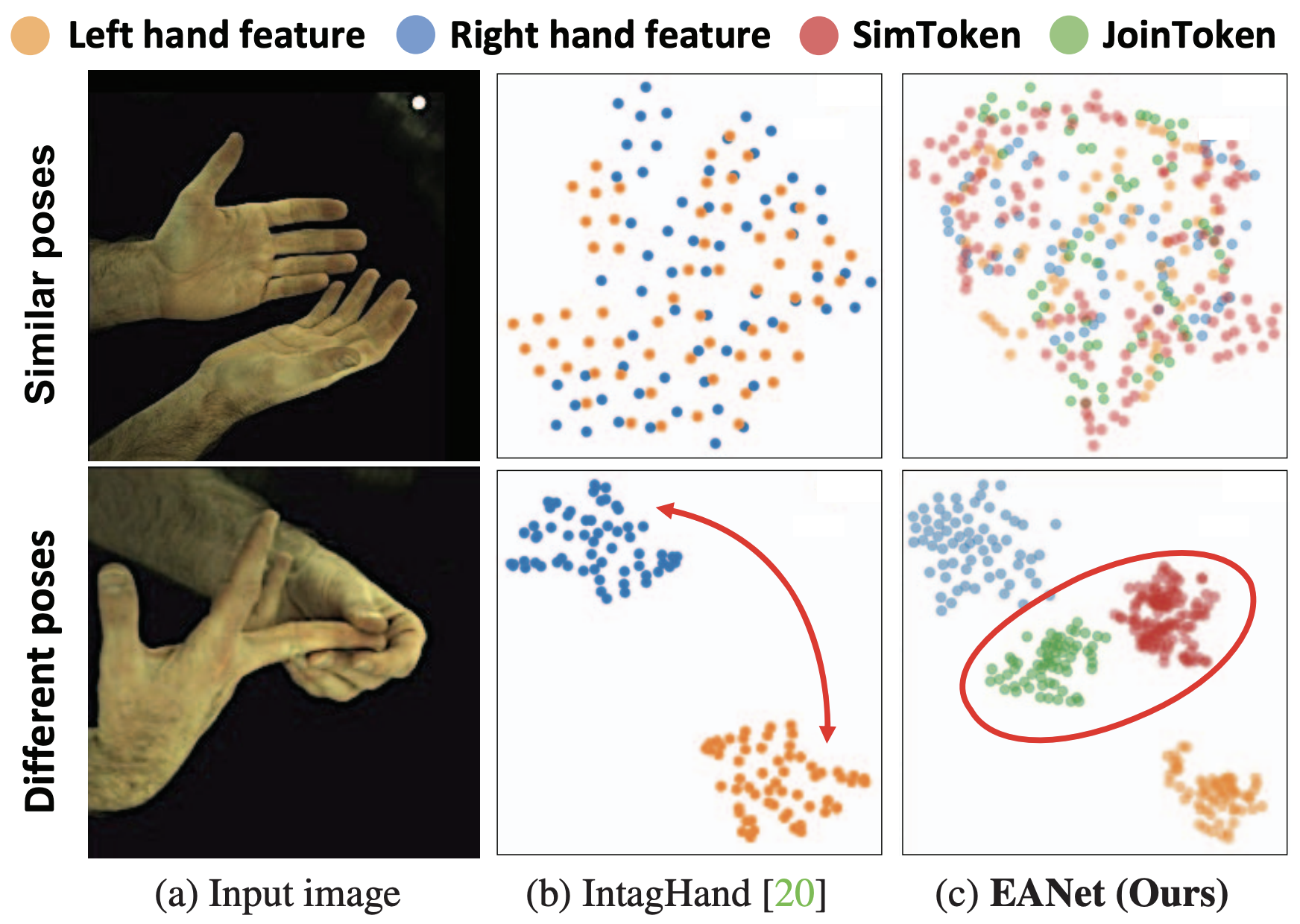 Extract-and-Adaptation Network for 3D Interacting Hand Mesh Recovery
Extract-and-Adaptation Network for 3D Interacting Hand Mesh Recovery
JoonKyu Park*, Daniel Sungho Jung*, Gyeongsik Moon*, Kyoung Mu Lee (* equal contribution)
International Conference on Computer Vision Workshops (ICCVW), 2023
paper / arxiv / code / Oral Presentation
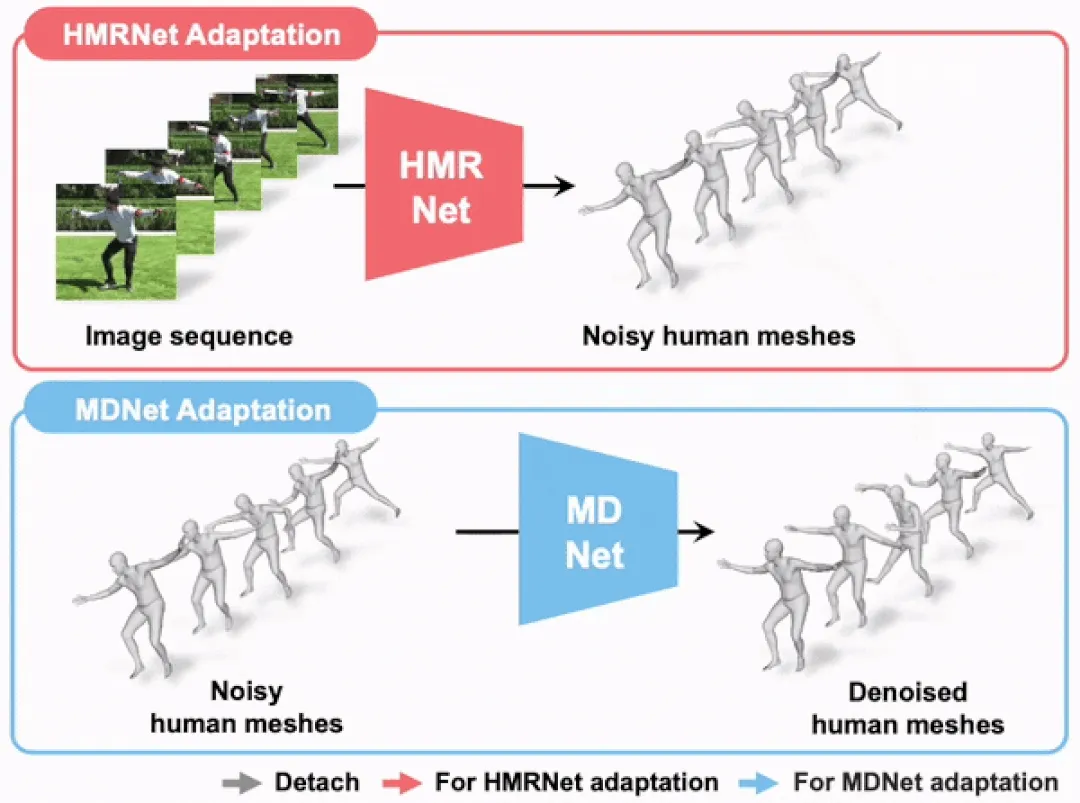 Cyclic Test-Time Adaptation on Monocular Video for 3D Human Mesh Reconstruction
Cyclic Test-Time Adaptation on Monocular Video for 3D Human Mesh Reconstruction
Hyeongjin Nam, Daniel Sungho Jung, Yeonguk Oh, Kyoung Mu Lee
International Conference on Computer Vision (ICCV), 2023
paper / arxiv / code
 RHOBIN Challenge: Reconstruction of Human Object Interaction
RHOBIN Challenge: Reconstruction of Human Object Interaction
Xianghui Xie, Xi Wang, Nikos Athanasiou, Bharat Lal Bhatnagar, Chun-Hao P. Huang, Kaichun Mo, Hao Chen, Xia Jia, Zerui Zhang, Liangxian Cui, Xiao Lin, Bingqiao Qian, Jie Xiao, Wenfei Yang, Hyeongjin Nam, Daniel Sungho Jung, Kihoon Kim, Kyoung Mu Lee, Otmar Hilliges, Gerard Pons-Moll
Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2023
project page / paper / arxiv / 1st Place Winner
Seoul National University
Ph.D. in Artificial Intelligence (Advisor: Prof. Kyoung Mu Lee)
Seoul, Republic of Korea
Mar 2022 - Present
The Pennsylvania State Univeristy
B.S. in Statistical Modeling Data Science (Advisor: Prof. Dongwon Lee, Prof. Kaamran Raahemifar)
University Park, Pennsylvania, United States of America
Aug 2017 - Dec 2021
SONY Group Corporation
Research Intern
Tokyo, Japan
Apr 2025 - Jul 2025
Korea Advanced Institute of Science and Technology (KAIST)
Visiting Student Researcher
Daejeon, Republic of Korea
Jun 2021 - Aug 2021
The Pennsylvania State University
Undergraduate Research Assistant
University Park, PA, USA
Aug 2019 - Sep 2020
Introduction to Robotics, Seoul National University
Head Teaching Assistant
Mar 2024 - Jun 2024
Introductory Microeconomic Analysis and Policy, The Pennsylvania State University
Teaching Assistant
Aug 2018 - May 2019
Address:
Office Location: Room 508
Email:
Phone: (+82) 02 880 6490